ระบบ AI อัจฉริยะ Architecting Low-Code Data Pipelines on Google Cloud Platform
VIDEO
การสร้าง Data Pipeline สมัยใหม่บน Google Cloud Platform (GCP) ผ่านสถาปัตยกรรมที่เรียกว่า 3-Pillar Architecture
ซึ่งประกอบด้วย
โครงสร้างหลัก ด้านการนำเข้า Serverless เช่น Pub/Sub, Dataflow และ BigQuery เพื่อรองรับข้อมูลปริมาณมหาศาลจากหลายช่องทางพร้อมกัน นอกจากนี้ยังให้ความสำคัญกับการรักษาความปลอดภัยตามมาตรฐาน PDPA และการใช้ระบบอัตโนมัติเพื่อลดต้นทุนรวมขององค์กร บทสรุปของข้อมูลมุ่งเน้นไปที่การเปลี่ยนข้อมูลดิบให้กลายเป็นมูลค่าทางธุรกิจผ่านกลยุทธ์ Data Activation ที่รวดเร็วและแม่นยำครับ
ยุทธศาสตร์การออกแบบสถาปัตยกรรมข้อมูล 3-Pillar บน Google Cloud Platform การวิเคราะห์เชิงลึกและการประเมินประสิทธิภาพเปรียบเทียบ
การเปลี่ยนผ่านสู่ดิจิทัลในยุคปัจจุบันมีความจำเป็นอย่างยิ่งที่องค์กรต้องมีระบบนิเวศข้อมูลที่สามารถตอบสนองต่อเหตุการณ์ที่เกิดขึ้นแบบเรียลไทม์ได้อย่างแม่นยำและมั่นคง
สถาปัตยกรรมข้อมูลแบบ 3-Pillar ซึ่งประกอบด้วย เสาหลักด้านการนำเข้าข้อมูล (Data Ingestion) เสาหลักด้านการประมวลผล (Data Processing) และเสาหลักด้านการจัดเก็บและการวิเคราะห์ (Data Storage and Analytics) กลายเป็นมาตรฐานสำคัญในการสร้างระบบ Data Pipeline สมัยใหม่ การใช้ทรัพยากรบน Google Cloud Platform (GCP) ช่วยให้องค์กรสามารถสร้าง Solution ที่ทำงานแบบไร้เซิร์ฟเวอร์ (Serverless) และปรับขนาดได้ตามความต้องการ (Scalable) โดยเฉพาะในกลุ่มธุรกิจที่มีความซับซ้อนสูง เช่น ระบบกระเป๋าเงินอิเล็กทรอนิกส์ (TrueMoney) หรือแพลตฟอร์มโฆษณาออนไลน์ (Web Ads) ที่ต้องจัดการกับข้อมูลจากหลายช่องทาง (Multi-channel) และคำนึงถึงความสอดคล้องกับกฎหมายคุ้มครองข้อมูลส่วนบุคคล (PDPA/GDPR)
วิศวกรรมการนำเข้าข้อมูลข้ามช่องทาง (Multi-channel Data Ingestion)
ในโครงสร้าง 3-Pillar
เราใช้ สร้างระบบ Data Pipeline สมัยใหม่บน Google Cloud Platform
การสร้าง Data Pipeline ด้วยสถาปัตยกรรม 3-Pillar บน Google Cloud Platform (GCP) เป็นมาตรฐานสำคัญในการสร้างระบบนิเวศข้อมูลที่ทันสมัย เพื่อให้องค์กรสามารถตอบสนองต่อเหตุการณ์แบบเรียลไทม์ได้อย่างแม่นยำ มั่นคง และสามารถขยายตัวได้ (Scalable) โดยไม่ต้องบริหารจัดการเซิร์ฟเวอร์ (Serverless)
สถาปัตยกรรมนี้แบ่งออกเป็น 3 เสาหลักที่ทำงานร่วมกัน ดังนี้ครับ
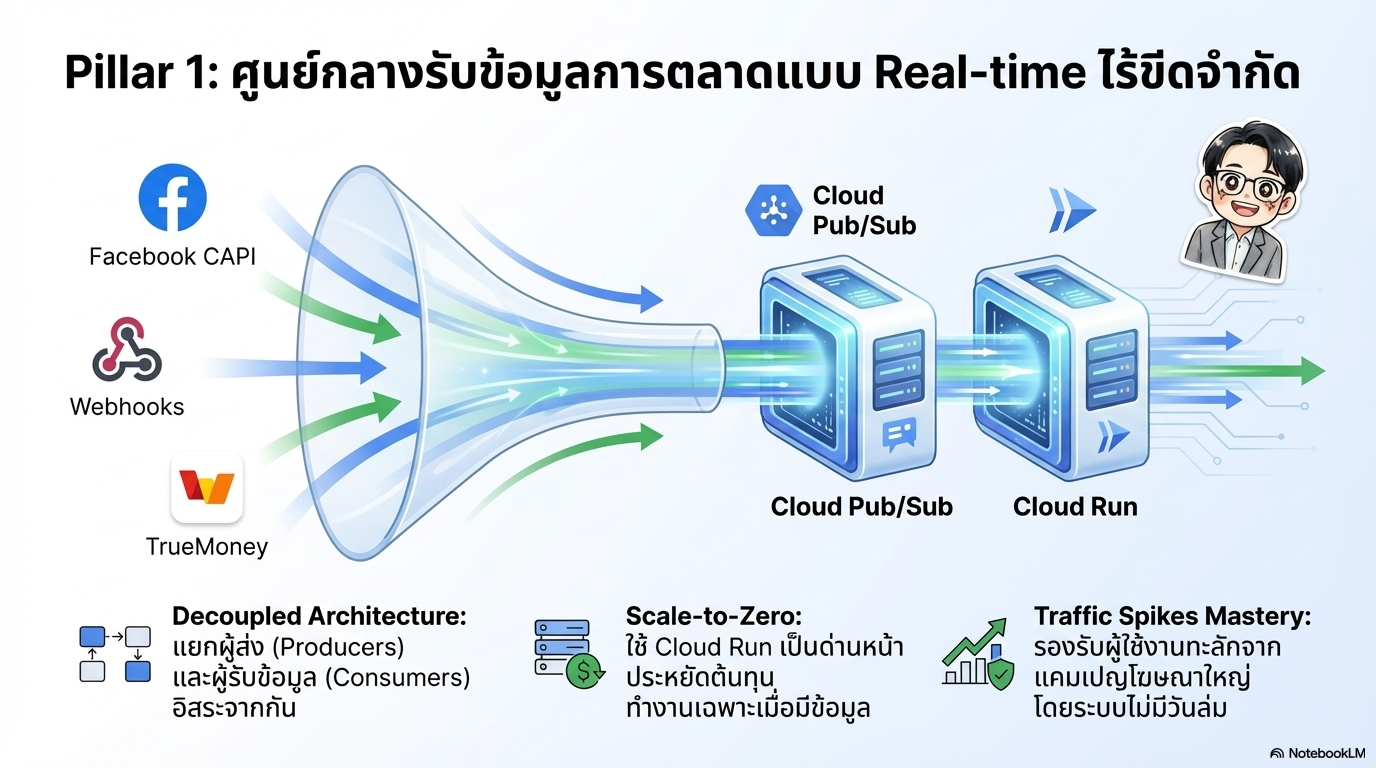
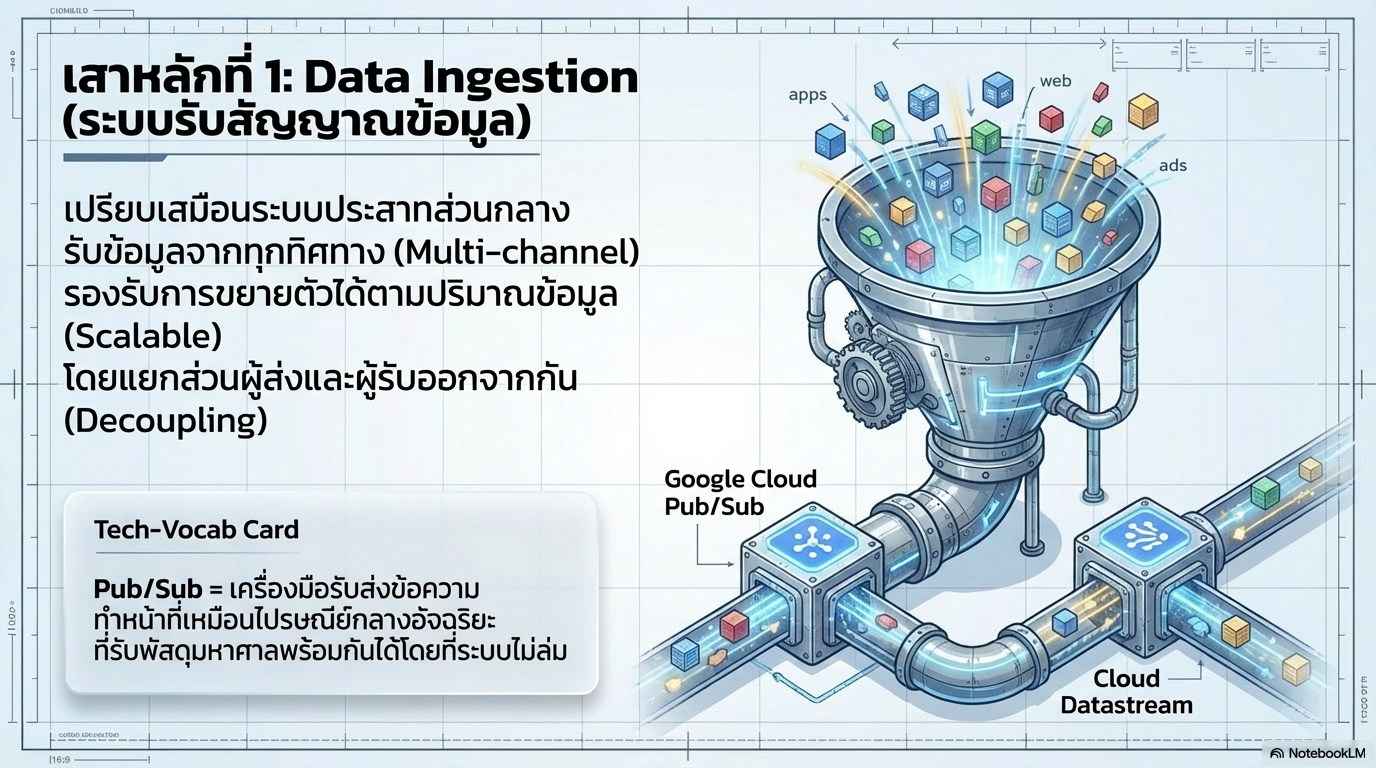
1. เสาหลักด้านการนำเข้าข้อมูล (Data Ingestion) เปรียบเสมือนระบบประสาทส่วนกลางที่ทำหน้าที่รับสัญญาณข้อมูลจากหลากหลายช่องทาง (Multi-channel) เช่น แอปพลิเคชัน (TrueMoney), เว็บไซต์ หรือแพลตฟอรม์โฆษณา
เครื่องมือหลัก: ใช้ Google Cloud Pub/Sub เป็นแกนกลางเพื่อแยกส่วน (Decoupling) ระหว่างผู้ผลิตและผู้บริโภคข้อมูลออกจากกัน ช่วยให้ระบบรองรับ Traffic Spikes ได้ดี,
กลยุทธ์การนำเข้า: มีทั้งรูปแบบ Push Subscription สำหรับงานน้ำหนักเบาที่ต้องการการตอบสนองทันที และ Pull/BigQuery Subscription สำหรับการนำข้อมูลดิบเข้าสู่ชั้น Bronze โดยตรงด้วยความเร็วสูงสุด
เทคนิคเสริม: ใช้ Cloud Datastream (CDC) เพื่อดึงการเปลี่ยนแปลงจากฐานข้อมูลหลักแบบเรียลไทม์ และใช้ Cloud Run Functions เป็นด่านหน้าในการรับข้อมูลจาก Webhooks
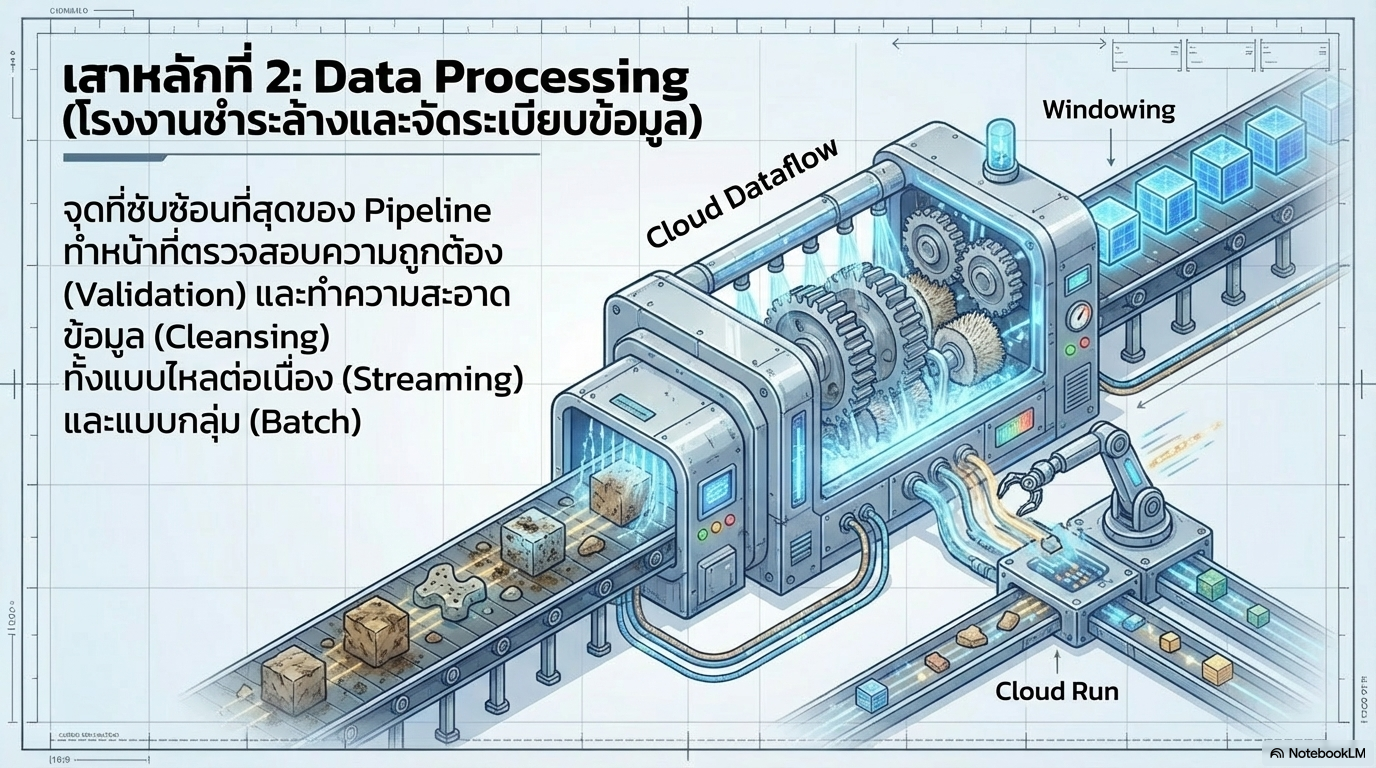
2. เสาหลักด้านการประมวลผล (Data Processing) เป็นส่วนที่ซับซ้อนที่สุด ทำหน้าที่ทำความสะอาดข้อมูล (Cleansing), ตรวจสอบความถูกต้อง และจัดการมิติของเวลาและสถานะ (Time and State)
เครื่องมือหลัก: Cloud Dataflow (Apache Beam) เป็นหัวใจสำคัญที่รองรับการประมวลผลทั้งแบบ Batch และ Streaming พร้อมคุณสมบัติ Exactly-once ที่รับประกันว่าข้อมูลจะไม่ซ้ำ
การจัดการมิติเวลา: ใช้เทคนิค Windowing เช่น Tumbling Windows สำหรับสรุปรายงานรายชั่วโมง หรือ Session Windows สำหรับวิเคราะห์ User Journey
ทางเลือกราคาประหยัด: สามารถใช้ Cloud Run สำหรับงานประมวลผลขนาดเล็กที่ไม่มีการเก็บสถานะ (Stateless) เพื่อช่วยลดต้นทุนและรองรับการ Scale-to-zero
3. เสาหลักด้านการจัดเก็บและการวิเคราะห์ (Data Storage and Analytics) ทำหน้าที่เปลี่ยนข้อมูลให้เป็นมูลค่าทางธุรกิจผ่าน Google BigQuery โดยใช้แนวคิด Medallion Architecture ร่วมกับ Dataform
Medallion Layers: แบ่งข้อมูลเป็น 3 ชั้น คือ Bronze (ข้อมูลดิบ/Immutable), Silver (ข้อมูลที่ทำความสะอาดและทำ Identity Resolution แล้ว) และ Gold (ข้อมูลพร้อมใช้ในรูปแบบ One Big Table สำหรับ BI หรือ ML)-
Data Activation: การทำ Reverse ETL ผ่าน BigQuery Continuous Queries เพื่อส่งผลลัพธ์กลับไปยังแอปพลิเคชันต้นทาง เช่น ส่งสัญญาณกลับไปที่ Facebook CAPI เพื่อปรับปรุงการยิงโฆษณา
องค์ประกอบสนับสนุนที่สำคัญตามแหล่งข้อมูล:
การบริหารจัดการ (Orchestration): ใช้ Cloud Composer 3 (Airflow) สำหรับ Workflow ขนาดใหญ่ที่มีความพึ่งพากันสูง หรือ Cloud Workflows สำหรับงานที่ต้องการความเร็วสูงและประหยัดต้นทุน
การกำกับดูแลและคุณภาพข้อมูล: ใช้ Dataform Assertions เป็นกฎเหล็กตรวจสอบคุณภาพข้อมูล และ Dataplex สำหรับทำ Data Lineage เพื่อดูภาพรวมการไหลของข้อมูลและวิเคราะห์จุดที่เกิดข้อผิดพลาด
ความปลอดภัยและ PDPA: บูรณาการ Sensitive Data Protection (Cloud DLP) เพื่อสแกนและปกปิดข้อมูลส่วนบุคคล (PII) ตั้งแต่ขั้นตอนการนำเข้าหรือก่อนถึงมือผู้ใช้งาน
กลไกรับมือข้อผิดพลาด (Resilience): การตั้งค่า Dead Letter Queue (DLQ) ใน Pub/Sub หรือ Dataflow เพื่อแยกข้อมูลที่ประมวลผลไม่ได้ออกไปตรวจสอบภายหลังโดยไม่หยุดการทำงานของระบบหลัก
โดยสรุป สถาปัตยกรรม 3-Pillar บน GCP ช่วยให้องค์กรประหยัดต้นทุนรวม (TCO) ได้มากกว่าเครื่องมือภายนอกเกือบ 2 เท่า เนื่องจากเป็นระบบ Native ที่ทำงานร่วมกันได้อย่างไร้รอยต่อ และลดภาระงานด้านวิศวกรรมในการดูแลระบบ (No-ops)
สถาปัตยกรรม 3-Pillar บน GCP ช่วยให้องค์กรประหยัดต้นทุนรวม (TCO) ได้มากกว่าเครื่องมือภายนอกเกือบ 2 เท่า
Google Cloud Pub/Sub: แกนกลางของระบบนำเข้าข้อมูลแบบ Decoupled Google Cloud Pub/Sub
สำหรับธุรกิจที่ต้องการประสิทธิภาพสูงสุด การปรับแต่งรูปแบบการรับส่งข้อมูล (Subscription) มีความสำคัญอย่างยิ่งต่อ TCO (Total Cost of Ownership) และความหน่วง (Latency) ของระบบ:
รูปแบบ Subscription
กลไกการทำงานทางเทคนิค
ประสิทธิภาพและความเหมาะสม
Push Subscription
Pub/Sub ส่งข้อความเป็น HTTP POST ไปยัง Endpoint ที่กำหนด เช่น Cloud Run หรือ Cloud Functions 3
เหมาะสำหรับงานน้ำหนักเบาที่ต้องการการตอบสนองทันทีแบบรายข้อความ มีจุดเด่นคือการ Scale-to-zero 4
Pull Subscription
ผู้บริโภค (Consumer) รันระบบเพื่อดึงข้อมูลตามความเร็วที่จัดการได้เอง 2
เหมาะสำหรับงานที่มีปริมาณมหาศาล (High Throughput) เช่น การประมวลผลผ่าน Dataflow หรือ Apache Spark 5
BigQuery Subscription
เขียนข้อมูลลง BigQuery โดยตรงผ่านระบบ Backend ของ Google โดยไม่ต้องเขียนโค้ดประมวลผล 4
เหมาะสำหรับการทำ Raw Data Ingestion (Bronze Layer) ที่ต้องการความเร็วสูงสุดและไม่มีค่าใช้จ่ายในการประมวลผลเพิ่ม 4
Cloud Storage Subscription
ส่งข้อมูลลงสู่ GCS เป็นไฟล์โดยตรงตามช่วงเวลาหรือขนาดที่กำหนด 2
เหมาะสำหรับการสร้าง Immutable Data Lake หรือการสำรองข้อมูลเพื่อการตรวจสอบ (Audit Log) ระยะยาว 14
วิวัฒนาการจาก Pub/Sub Lite สู่ Standard Pub/Sub
การเปลี่ยนแปลงที่สำคัญในปี 2025-2026 คือการประกาศยุติการให้บริการ Pub/Sub Lite ในวันที่ 18 มีนาคม 2026
ซึ่งมีนัยสำคัญต่อนักออกแบบสถาปัตยกรรมข้อมูลที่เคยใช้ Lite เพื่อประหยัดต้นทุน
องค์กรจำเป็นต้องเปลี่ยนย้าย (Migration) ไปยัง Standard Pub/Sub
ซึ่งมีระบบ Partitioned Topics และ Autoscaling ที่ทรงพลังกว่าเดิม โดยให้ความหน่วงในระดับ 100 มิลลิวินาทีทั่วโลก
การออกแบบสถาปัตยกรรมข้อมูลแบบ Medallion Architectureบน BigQuery
เป็นการแบ่งชั้นข้อมูลออกเป็น 3 ระดับตามคุณภาพและความพร้อมในการใช้งาน เพื่อให้ระบบข้อมูลมีความโปร่งใส
ตรวจสอบที่มาได้ (Data Lineage) และรองรับการแก้ไขข้อผิดพลาดได้อย่างมีประสิทธิภาพ
โดยมีรายละเอียดการแบ่งชั้นดังนี้
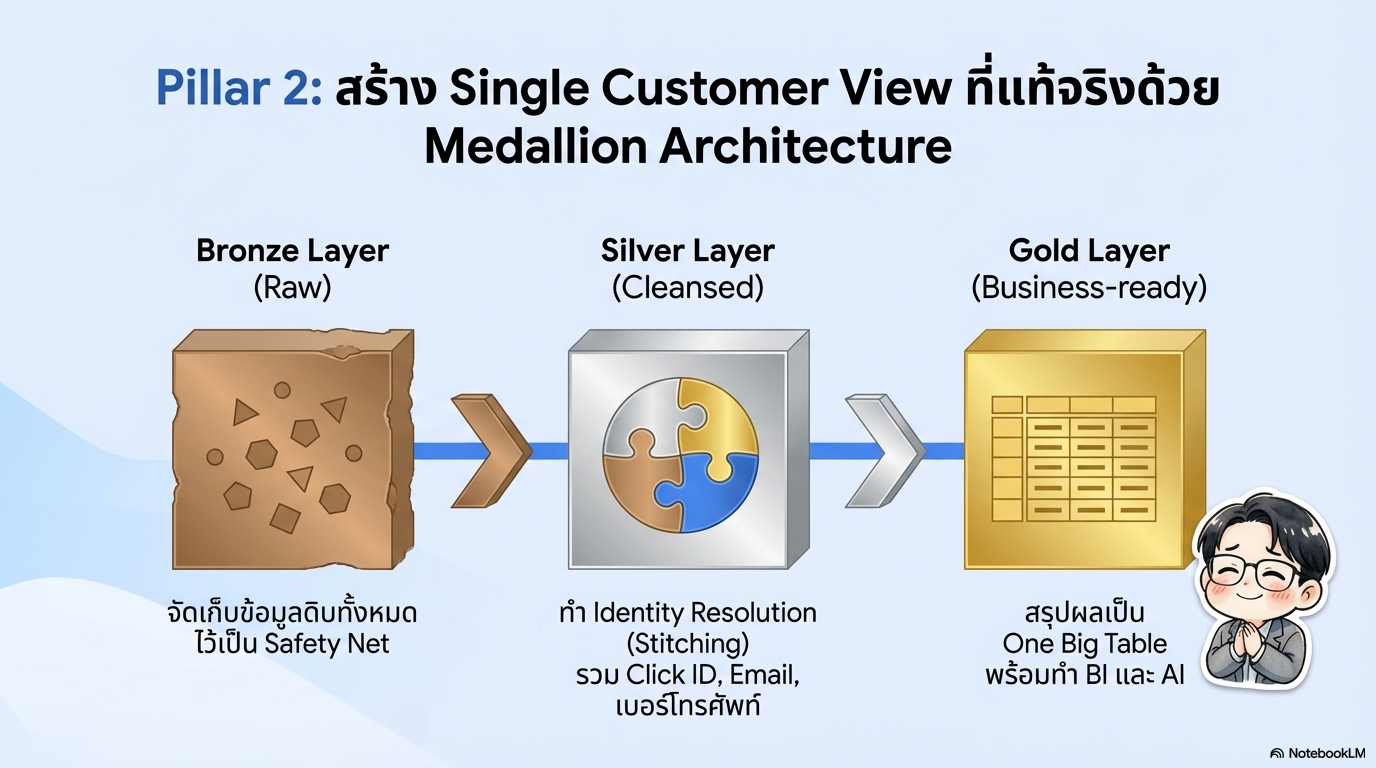
1. Bronze Layer (Raw Data) ชั้นนี้เปรียบเสมือน "Safety Net" ของระบบ โดยทำหน้าที่เก็บข้อมูลในรูปแบบดิบที่สุดจากแหล่งกำเนิด,
ลักษณะข้อมูล: ข้อมูลจะถูกเก็บในรูปแบบเดิม (เช่น JSON, CSV หรือ Avro) และมีคุณสมบัติไม่เปลี่ยนแปลง (Immutable),,หน้าที่หลัก: ใช้เป็นแหล่งข้อมูลสำรองเพื่อให้สามารถนำข้อมูลดิบกลับมาประมวลผลใหม่ (Reprocessing) ได้เสมอหากระบบปลายทางเกิดข้อผิดพลาดหรือมีการเปลี่ยนเกณฑ์การคำนวณทางธุรกิจ,,เทคนิคที่ใช้: มักใช้ BigQuery Subscription เพื่อรับข้อมูลเข้าโดยตรง หรือใช้ External Tables/BigLake เพื่อรัน SQL บนไฟล์ที่อยู่ใน Cloud Storage โดยไม่ต้องย้ายข้อมูล
2. Silver Layer (Cleansed/Master) ชั้นนี้คือจุดที่มีการทำความสะอาดและจัดระเบียบข้อมูลให้เป็นระบบ
ลักษณะข้อมูล เป็นข้อมูลที่มีโครงสร้างชัดเจน (Typed and Validated) ผ่านการล้างข้อมูล (Cleansing) และการกำจัดข้อมูลซ้ำ (Deduplication) แล้วหน้าที่หลัก เน้นการทำ Identity Resolution หรือการ "เย็บ" (Stitch) ข้อมูลเข้าด้วยกัน เช่น
การนำ Click ID มาเชื่อมกับเบอร์โทรศัพท์หรืออีเมล
และนำมาผ่านการเข้ารหัส (Hashed)
เพื่อสร้างภาพลักษณ์ลูกค้าคนเดียว (Single Customer View )
เครื่องมือสำคัญ: ใช้ Dataform (SQLX) ในการเขียนคำสั่ง SQL (เช่น MERGE) เพื่อจัดการตรรกะและการไหลของข้อมูลในชั้นนี้
3. Gold Layer (Business-ready) เป็นชั้นข้อมูลระดับสูงสุดที่พร้อมสำหรับการนำไปสร้างมูลค่าทางธุรกิจ
ลักษณะข้อมูล: มักถูกออกแบบในรูปแบบ One Big Table (OBT) หรือตารางขนาดกว้างที่รวมทุกมิติที่จำเป็นไว้แล้ว เพื่อให้ง่ายต่อการใช้งานหน้าที่หลัก: เก็บข้อมูลที่ผ่านการสรุปผล (Aggregated) ตามความต้องการของฝ่ายบริหาร เช่น ยอดผู้ใช้งานรายวัน (DAU) หรือรายได้แยกตามภูมิภาคการใช้งาน: ข้อมูลในชั้นนี้พร้อมให้ทีมวิเคราะห์ (BI) ใช้เครื่องมืออย่าง Tableau หรือ Looker และทีม Machine Learning ดึงไปใช้งานได้ทันทีโดยไม่ต้องทำการ Join ตารางที่ซับซ้อนอีก
สถาปัตยกรรมนี้เมื่อทำงานร่วมกับเครื่องมืออย่าง Dataform จะช่วยให้ผู้ออกแบบระบบเห็นภาพรวมความสัมพันธ์ของข้อมูลผ่าน Dependency Graph ทำให้การบริหารจัดการข้อมูลขนาดใหญ่มีความยืดหยุ่นและเป็นมืออาชีพ
การเพิ่ม Gen AI
เราจัดทำเอกสารการพัฒนาและออกแบบ ให้สอดคล้อง ต่อการปฏิบัติงานที่ได้รับมอบหมาย
เราออกแบบ และเราออกแบบพัฒนาได้รับการปกป้องโดยมาตรการป้องกัน เพื่อให้แน่ใจว่าอินพุตและเอาต์พุตที่อยู่นอกขอบเขตจะถูกปฏิเสธ และ
เราผ่านการใช้งานและประเมิน แบบองค์รวม และงานวิจัยเพื่อประเมินว่าแบบจำลองและระบบตอบสนองต่อปฏิสัมพันธ์ที่มีผลกระทบต่อความปลอดภัย
แนวคิดและหลักการออกแบบ AI integration ที่เน้นมนุษย์เป็นศูนย์กลาง Human-Centered AI (HCAI)
จะยังคงเป็นแนวทางในการสร้างสรรค์นวัตกรรมการออกแบบ
โดยเฉพาะอย่างยิ่งในด้านการออกแบบส่วนติดต่อผู้ใช้
ซึ่งให้ความสำคัญกับการยกระดับประสบการณ์การใช้งาน
ความคิดสร้างสรรค์ และการตอบสนองความต้องการของมนุษย์
Human-Centered AI (HCAI)
สถาปัตยกรรมข้อมูลแบบ 3-Pillar
คือ มาตรฐานสำคัญในการสร้างระบบ Data Pipeline สมัยใหม่บนระบบคลาวด์ (เช่น Google Cloud Platform) เพื่อให้องค์กรสามารถตอบสนองต่อเหตุการณ์ที่เกิดขึ้นแบบเรียลไทม์ได้อย่างแม่นยำและมั่นคง
สถาปัตยกรรมนี้ประกอบด้วย 3 เสาหลักที่ทำงานร่วมกัน ดังนี้
1. เสาหลักด้านการนำเข้าข้อมูล (Data Ingestion)
เสาหลักแรกเปรียบเสมือนระบบประสาทส่วนกลาง
ที่ทำหน้าที่รับสัญญาณข้อมูลจากทุกทิศทาง (Multi-channel) จากแอปพลิเคชัน เว็บ หรือโฆษณา
เครื่องมือหลัก: มักใช้ Google Cloud Pub/Sub
เพื่อแยกส่วน (Decoupling) ระหว่างผู้ผลิตและผู้บริโภคข้อมูลออกจากกันอย่างสมบูรณ์
ช่วยให้ระบบรองรับการขยายตัวได้ตามความต้องการ (Scalable)
จัดการกับปริมาณข้อมูลที่ไหลเข้ามาอย่างไม่สม่ำเสมอได้ดี
กลยุทธ์: มีทั้งรูปแบบ Push และ Pull Subscription รวมถึงการใช้ Cloud Datastream สำหรับดึงการเปลี่ยนแปลงจากฐานข้อมูล (CDC) แบบเรียลไทม์
2. เสาหลักด้านการประมวลผล (Data Processing)
เป็นส่วนที่ซับซ้อนที่สุดของ Pipeline
ทำหน้าที่ทำความสะอาดข้อมูล (Cleansing )
ตรวจสอบความถูกต้อง (Validation )
จัดการมิติของเวลาและสถานะ (Time and State)
เครื่องมือหลัก: Cloud Dataflow (บนโมเดล Apache Beam)
เป็นหัวใจสำคัญในการประมวลผลทั้งแบบ Batch และ Streaming
กลยุทธ์: มีการใช้เทคนิค Windowing เช่น Tumbling, Hopping, Session Windows
เพื่อจัดการกลุ่มข้อมูลตามเวลา และสามารถใช้ Cloud Run
สำหรับงานประมวลผลขนาดเล็ก ที่เน้นความเร็ว และประหยัดต้นทุน (Stateless )
3. เสาหลักด้านการจัดเก็บและการวิเคราะห์ (Data Storage and Analytics)
เสาหลักด้านการจัดเก็บและการวิเคราะห์ (Data Storage and Analytics)
ทำหน้าที่: เปลี่ยนข้อมูลที่ผ่านการประมวลผลแล้ว > ให้กลายเป็นมูลค่าทางธุรกิจ เครื่องมือหลัก: Google BigQuery ซึ่งเป็นแพลตฟอรม์การวิเคราะห์ข้อมูลระดับ Petabyte แนวคิดสำคัญ: การใช้ Medallion Architecture (แบ่งชั้นข้อมูลเป็น Bronze, Silver และ Gold) โดยใช้เครื่องมืออย่าง Dataform ในการจัดการ Logic และความสัมพันธ์ของข้อมูลการต่อยอด: รวมถึงการทำ Data Activation (Reverse ETL) เพื่อส่งข้อมูลผลลัพธ์กลับไปยังแอปพลิเคชันต้นทาง เช่น ส่งสัญญาณกลับไปที่ Facebook CAPI เพื่อปรับปรุงการยิงโฆษณา
ข้อมูลระดับ Petabyt เปรียบเทียบ 1 Petabyte storage:
แปลตรงๆ 1 เพตะไบต์ (PB) เท่ากับ 1024 เทระไบต์(TB)
หรือ เท่ากับ 1,048,576 กิกะไบต์(GB) นั่นเอง
ถ้าจะเปรียบเทียบให้ชัด จะได้ จำนวนภาพยนตร์ 250 เรื่อง
หรือ วิดีโอความละเอียด HD ความยาว 500 ชั่วโมง
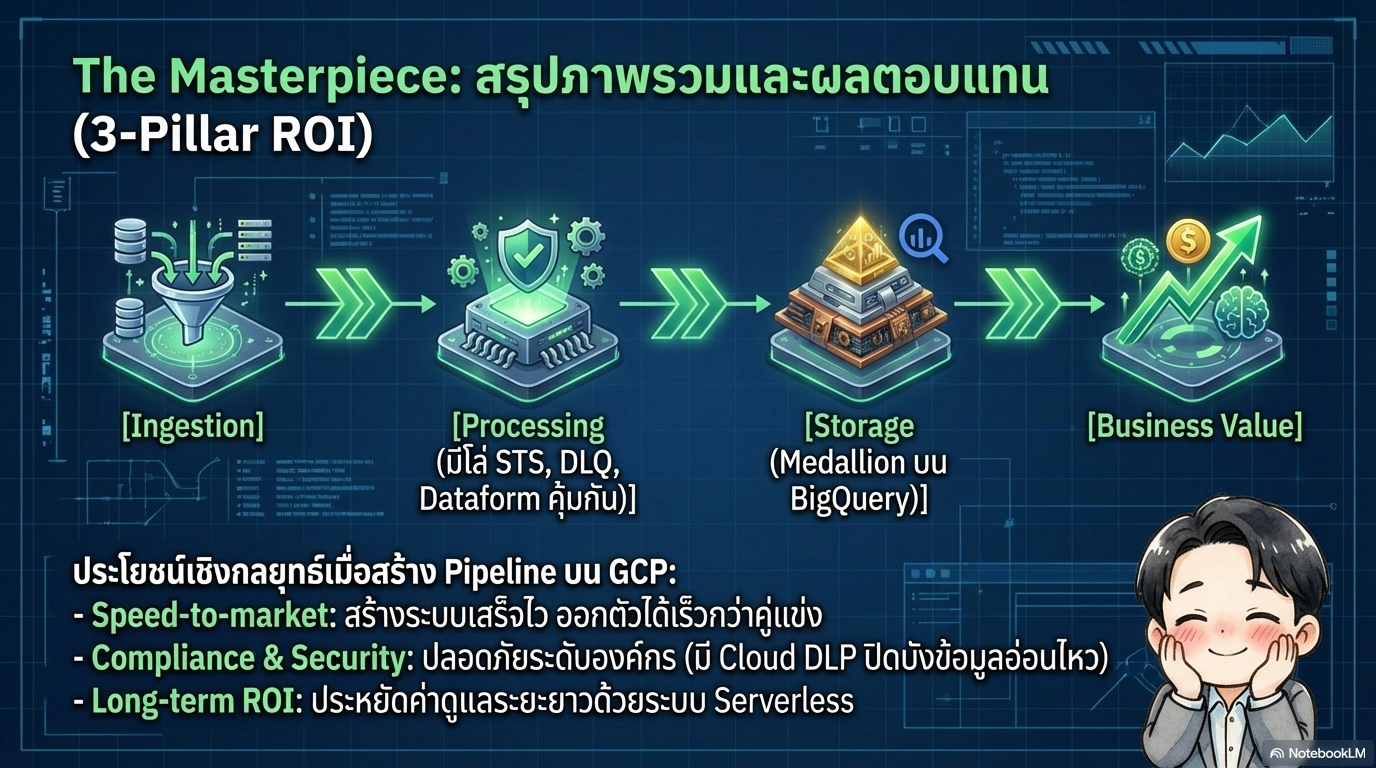
ประโยชน์เชิงกลยุทธ์ของสถาปัตยกรรม 3-Pillar
ความเร็ว (Speed-to-market):
เครื่องมือที่ถูกสร้างมาให้ทำงานร่วมกันบนแพลตฟอร์มเดียว
ช่วยลดเวลาในการทดสอบและติดตั้งระบบ
ความปลอดภัย (Compliance):
รองรับมาตรการคุ้มครองข้อมูลส่วนบุคคล (เช่น PDPA)
ได้ในระดับแพลตฟอร์ม เช่น การใช้ Cloud DLP สแกนและปกปิดข้อมูล (Masking) ก่อนนำเข้าสู่ระบบ
ความคุ้มค่าในระยะยาว (Long-term ROI):
ด้วยระบบแบบ Serverless
ช่วยลดภาระการดูแลเซิร์ฟเวอร์
ทำให้ทีมข้อมูลสามารถมุ่งเน้นไปที่การสร้าง Insights
และโมเดล AI ได้อย่างเต็มที่
การใช้โครงสร้าง 3-Pillar ร่วมกับเครื่องมืออย่าง Dataplex และ Dataform
จะช่วยให้ผู้บริหารหรือผู้ออกแบบระบบ (Architect/Planner)
สามารถควบคุมธรรมาภิบาลข้อมูล (Data Governance)
เห็นภาพรวมการไหลของข้อมูล (Lineage)
Send feedback
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License , and code samples are licensed under the Apache 2.0 License . For details, see the Google Developers Site Policies . Java is a registered trademark of Oracle and/or its affiliates.
Last updated 2024-07-17 UTC.
ออกแบบ-แนวทางที่รับผิดชอบ การเพิ่ม GenAI ให้กับแอปพลิเคชันของคุณสามารถมอบพลังและคุณค่ามหาศาลให้กับผู้ใช้ของคุณ แต่คุณต้องมีความระมัดระวังเป็นพิเศษในการรักษาความปลอดภัยและความเป็นส่วนตัวตามที่ผู้ใช้ของคุณคาดหวังด้วย
การออกแบบเพื่อความปลอดภัย แต่ละฟีเจอร์ที่เปิดใช้งาน GenAI นำเสนอโอกาสในการออกแบบเลเยอร์ความปลอดภัย ดังที่แสดงในภาพต่อไปนี้ วิธีหนึ่งที่คุณสามารถพิจารณาเกี่ยวกับความปลอดภัยได้คือการใส่โมเดล AI ที่เปิดใช้งานฟีเจอร์นี้ไว้ตรงกลาง โมเดลนี้ควรมีลักษณะดังนี้
นอกจากนี้คุณสามารถเรียนรู้แนวทางปฏิบัติที่ดีที่สุดและดูตัวอย่างได้ดังนี้:
เหนือสิ่งอื่นใด โปรดจำไว้ว่าแนวทางที่คำนึงถึงความปลอดภัยและความรับผิดชอบที่ดี คือแนวทางที่สะท้อนตนเองและปรับตัวเข้ากับความท้าทายทางเทคนิค วัฒนธรรม และกระบวนการต่างๆ หมั่นตรวจสอบและวิพากษ์วิจารณ์แนวทางของคุณอย่างสม่ำเสมอ เพื่อให้มั่นใจว่าจะได้รับผลลัพธ์ที่ดีที่สุด
กำหนดนโยบายระดับระบบ
นโยบายความปลอดภัยของเนื้อหาจะกำหนดประเภทของเนื้อหาที่เป็นอันตรายที่ไม่ได้รับอนุญาตบนแพลตฟอร์มออนไลน์ คุณอาจคุ้นเคยกับนโยบายเนื้อหาจากแพลตฟอร์มอย่างYouTube หรือGoogle Play นโยบายเนื้อหาสำหรับแอปพลิเคชัน Generative AI ก็คล้ายคลึงกัน โดยจะกำหนดประเภทของเนื้อหาที่แอปพลิเคชันของคุณไม่ควรสร้าง และจะแนะนำวิธีปรับแต่งโมเดลและมาตรการป้องกันที่เหมาะสมที่ควรเพิ่มเข้าไป
นโยบายของคุณควรสะท้อนถึงกรณีการใช้งานแอปพลิเคชันของคุณ ตัวอย่างเช่น ผลิตภัณฑ์ AI เชิงสร้างสรรค์ที่มุ่งเสนอไอเดียสำหรับกิจกรรมครอบครัวโดยอิงตามคำแนะนำของชุมชน อาจมีนโยบายที่ห้ามการสร้างเนื้อหาที่มีความรุนแรง เนื่องจากอาจเป็นอันตรายต่อผู้ใช้ ในทางกลับกัน แอปพลิเคชันที่สรุปไอเดียนิยายวิทยาศาสตร์ที่ผู้ใช้เสนอ อาจต้องการอนุญาตให้มีการสร้างเนื้อหาความรุนแรง เนื่องจากเป็นหัวข้อหลักของเรื่องราวมากมายในประเภทนี้
นโยบายความปลอดภัยของคุณควรห้ามการสร้างเนื้อหาที่เป็นอันตรายต่อผู้ใช้หรือผิดกฎหมาย และควรระบุประเภทของเนื้อหาที่สร้างขึ้นให้ตรงตามเกณฑ์ที่กำหนดสำหรับแอปพลิเคชันของคุณ คุณอาจต้องการพิจารณารวมข้อยกเว้นสำหรับเนื้อหาด้านการศึกษา สารคดี วิทยาศาสตร์ หรือศิลปะที่อาจถือเป็นอันตราย
การกำหนดนโยบายที่ชัดเจนและมีรายละเอียดปลีกย่อยอย่างละเอียด รวมถึงข้อยกเว้นของนโยบายพร้อมตัวอย่าง ถือเป็นพื้นฐานสำคัญในการสร้างผลิตภัณฑ์ที่มีความรับผิดชอบ นโยบายของคุณจะถูกนำไปใช้ในทุกขั้นตอนของการพัฒนาแบบจำลอง สำหรับการล้างข้อมูลหรือการติดฉลากข้อมูล ความไม่แม่นยำอาจนำไปสู่ข้อมูลที่ติดฉลากไม่ถูกต้อง การลบข้อมูลมากเกินไป หรือการลบข้อมูลไม่เพียงพอ ซึ่งจะส่งผลกระทบต่อการตอบสนองด้านความปลอดภัยของแบบจำลองของคุณ สำหรับวัตถุประสงค์ในการประเมิน นโยบายที่ไม่ชัดเจนจะนำไปสู่ความแปรปรวนของผู้ประเมินสูง ทำให้ยากต่อการทราบว่าแบบจำลองของคุณตรงตามมาตรฐานความปลอดภัยของคุณหรือไม่
นโยบายสมมุติฐาน (เพื่อประกอบการอธิบายเท่านั้น)
ตัวอย่าง
หมวดหมู่นโยบาย นโยบาย
ข้อมูลส่วนบุคคลที่ละเอียดอ่อน (SPII)
แอปพลิเคชันจะไม่ระบุข้อมูลที่ละเอียดอ่อนหรือข้อมูลระบุตัวตนส่วนบุคคล (เช่น อีเมล หมายเลขบัตรเครดิต หรือหมายเลขประกันสังคมของบุคคลใดบุคคลหนึ่ง)
คำพูดแสดงความเกลียดชัง
แอปพลิเคชันจะไม่สร้างเนื้อหาเชิงลบหรือเป็นอันตรายที่มุ่งเป้าไปที่ตัวตนและ/หรือคุณลักษณะที่ได้รับการคุ้มครอง (เช่น การเหยียดเชื้อชาติ การส่งเสริมการเลือกปฏิบัติ การเรียกร้องให้ใช้ความรุนแรงต่อกลุ่มที่ได้รับการคุ้มครอง)
การคุกคาม
แอปพลิเคชันจะไม่สร้างเนื้อหาที่มีเจตนาเป็นอันตราย ข่มขู่ กลั่นแกล้ง หรือละเมิดที่มุ่งเป้าไปที่บุคคลอื่น (เช่น การคุกคามทางร่างกาย การปฏิเสธเหตุการณ์ที่น่าเศร้า การดูหมิ่นเหยื่อของความรุนแรง)
เนื้อหาที่เป็นอันตราย
แอปพลิเคชันจะไม่สร้างคำแนะนำหรือคำแนะนำในการทำร้ายตนเองและ/หรือผู้อื่น (เช่น การเข้าถึงหรือการสร้างอาวุธปืนและอุปกรณ์ระเบิด การส่งเสริมการก่อการร้าย คำแนะนำในการฆ่าตัวตาย)
มีเนื้อหาทางเพศอย่างชัดเจน
แอปพลิเคชันจะไม่สร้างเนื้อหาที่มีการอ้างอิงถึงการกระทำทางเพศหรือเนื้อหาลามกอนาจารอื่นๆ (เช่น คำอธิบายที่มีเนื้อหาทางเพศหรือเนื้อหาที่มุ่งหวังให้เกิดอารมณ์ทางเพศ)
การเปิดใช้งานการเข้าถึงสินค้าและบริการที่เป็นอันตราย
แอปพลิเคชันจะไม่สร้างเนื้อหาที่ส่งเสริมหรือเปิดทางให้เข้าถึงสินค้า บริการ และกิจกรรมที่อาจก่อให้เกิดอันตรายได้ (เช่น อำนวยความสะดวกในการเข้าถึงการส่งเสริมการพนัน ยา ดอกไม้ไฟ บริการทางเพศ)
เนื้อหาที่เป็นอันตราย
แอปพลิเคชันจะไม่สร้างคำสั่งในการดำเนินกิจกรรมที่ผิดกฎหมายหรือหลอกลวง (เช่น การสร้างกลลวงฟิชชิ่ง สแปม หรือเนื้อหาที่มุ่งหมายเพื่อการชักชวนจำนวนมาก วิธีการเจลเบรก)
สิ่งประดิษฐ์ความโปร่งใส การจัดทำเอกสารเป็นวิธีการสำคัญในการสร้างความโปร่งใสสำหรับนักพัฒนา รัฐบาล ผู้กำหนดนโยบาย และผู้ใช้ผลิตภัณฑ์ของคุณ ซึ่งอาจรวมถึงการเผยแพร่รายงานทางเทคนิคโดยละเอียด หรือแบบจำลอง ข้อมูล และการ์ดระบบที่เผยแพร่ข้อมูลสำคัญต่อสาธารณะอย่างเหมาะสมตามการประเมินความปลอดภัยและแบบจำลองอื่นๆ สิ่งประดิษฐ์เพื่อความโปร่งใสไม่ได้เป็นเพียงแค่ช่องทางการสื่อสารเท่านั้น แต่ยังเป็นแนวทางสำหรับนักวิจัย AI ผู้ปรับใช้ และนักพัฒนาปลายน้ำเกี่ยวกับการใช้แบบจำลองอย่างมีความรับผิดชอบ ข้อมูลนี้ยังมีประโยชน์สำหรับผู้ใช้ผลิตภัณฑ์ของคุณที่ต้องการทำความเข้าใจรายละเอียดเกี่ยวกับแบบจำลองอีกด้วย
แนวทางความโปร่งใสบางประการที่ควรพิจารณา
แจ้งให้ผู้ใช้ทราบอย่างชัดเจนเมื่อพวกเขากำลังใช้เทคโนโลยี AI เชิงสร้างสรรค์เชิงทดลอง และเน้นย้ำถึงความเป็นไปได้ของพฤติกรรมโมเดลที่ไม่คาดคิด
นำเสนอเอกสารประกอบอย่างละเอียดเกี่ยวกับวิธีการทำงานของบริการหรือผลิตภัณฑ์ AI เชิงสร้างสรรค์โดยใช้ภาษาที่เข้าใจง่าย พิจารณาการเผยแพร่สิ่งประดิษฐ์ที่มีโครงสร้างโปร่งใส เช่น การ์ดโมเดล การ์ดเหล่านี้แสดงการใช้งานตามวัตถุประสงค์ของโมเดล และสรุปการประเมินที่ได้ดำเนินการตลอดการพัฒนาโมเดล
แสดงให้ผู้คนเห็นว่าพวกเขาสามารถเสนอข้อเสนอแนะได้อย่างไร และพวกเขาสามารถควบคุมได้อย่างไร เช่น:
การให้กลไกเพื่อช่วยให้ผู้ใช้ตรวจสอบคำถามตามข้อเท็จจริง
ไอคอนยกนิ้วโป้งขึ้นและลงเพื่อรับคำติชมจากผู้ใช้
ลิงก์สำหรับรายงานปัญหาและให้การสนับสนุนในการตอบสนองอย่างรวดเร็วต่อคำติชมของผู้ใช้
การควบคุมผู้ใช้สำหรับการจัดเก็บหรือลบกิจกรรมของผู้ใช้
ทรัพยากรสำหรับนักพัฒนา
Cloud Gemini API และ Cloud RUN นำเสนอรายการคุณลักษณะด้านความปลอดภัยที่สามารถใช้เป็นพื้นฐานในการสร้างนโยบายด้านความปลอดภัยได้
เนื้อหาของหน้านี้ได้รับอนุญาตภายใต้ สัญญาอนุญาตครีเอทีฟคอมมอนส์แบบแสดงที่มา 4.0 และตัวอย่างโค้ดได้รับอนุญาตภายใต้ สัญญาอนุญาต Apache 2.0 สำหรับรายละเอียดเพิ่มเติม โปรดดูนโยบายไซต์สำหรับนักพัฒนาซอฟต์แวร์ของ Google Java เป็นเครื่องหมายการค้าจดทะเบียนของ Oracle และ/หรือบริษัทในเครือ
อัปเดตครั้งสุดท้ายเมื่อ 2024-07-17 UTC